Le référencement n’est pas qu’un jeu de mots-clés ou de contenus léchés. Il exige aussi une plongée régulière dans les entrailles de son site et de ceux des autres : analyser les flux, les liens, l’indexation, les réactions des utilisateurs, la structure interne, sans oublier l’environnement tissé par les backlinks. Pour tous ceux qui veulent vraiment comprendre et améliorer leur site, il faut un outil robuste, capable de scanner chaque recoin et de livrer des diagnostics précis.
Vous le savez déjà, rien qu’en lisant le titre : je me fie au logiciel SEO Spider de Screaming Frog pour mes analyses (la version gratuite couvre déjà un large spectre !). Voici 7 méthodes concrètes pour tirer des données précieuses de cet outil et affiner votre référencement. Si vous souhaitez l’essayer, l’outil se télécharge ici.
A lire aussi : Application IPTV : comment l'installer ?
Si l’optimisation technique vous paraît encore obscure, que les termes comme « hreflang », « JavaScript » ou « 404 » vous font froncer les sourcils, vous trouverez plus bas des ressources pour vous aider à apprivoiser tout ça.
Prêt à soulever le capot et à explorer ce qui se cache derrière les pages de votre site ? On y va.
A voir aussi : Vider la corbeille sur Android étape par étape, même si vous n'êtes pas à l'aise avec le téléphone
- Détecter les URL et liens brisés
- Optimiser la structure de liens internes
- Repérer les redirections inutiles
- Observer la manière dont Googlebot traite vos pages
- Traquer les erreurs Hreflang sur les sites multilingues
- Identifier les problèmes de contenu mixte
- Évaluer la profondeur et l’accessibilité des pages
1. Détecter les URL et liens brisés
Page 404 par Pixar Studios, Creative : creativebloq.com
Les erreurs 404 grignotent encore les performances SEO, souvent là où on les attend le moins. Ce code ne ruine pas un site, mais rater la chasse aux 404, c’est risquer de casser la navigation et de véhiculer une image d’amateurisme tant auprès des robots que des visiteurs.
Un contrôle fréquent s’avère donc salutaire pour garder son site fluide.
Voici comment Screaming Frog aide à relever ces erreurs :
1. Lancez un scan du site, ou d’une section particulière pour cibler un périmètre précis.
2. Dans l’onglet des codes de réponse, appliquez le filtre sur les 4xx pour voir apparaître directement les liens à reprendre.
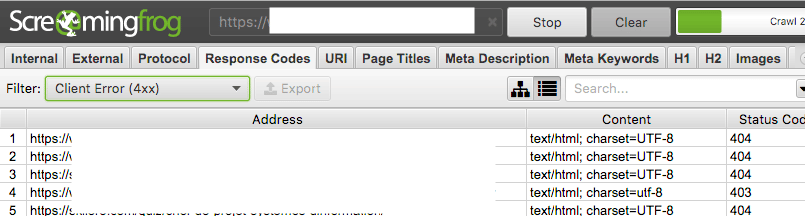
3. Depuis le menu « Export en masse », extraire le rapport « Liens entrants d’erreur client (4xx) » pour inspecter en détail ce qui cause ces impasses.
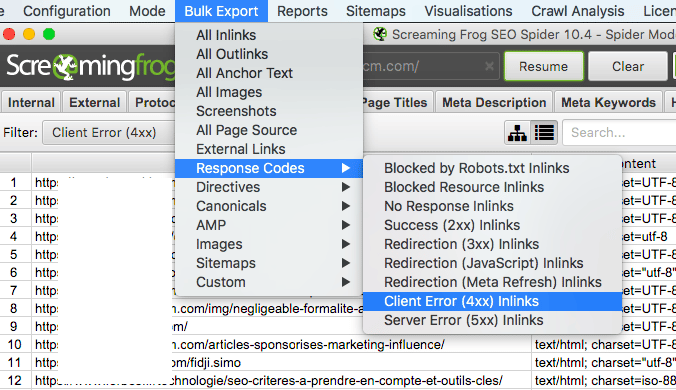
4. En important le fichier dans un tableur, toutes les informations utiles apparaissent : page source, cible, type d’erreur. Il devient alors bien plus facile de réparer les maillons faibles du site.
À noter : le même principe fonctionne pour identifier rapidement des erreurs 3xx et 5xx.
2. Optimiser la structure de liens internes

Crédit : stock.adobe.com
Le maillage interne forge le parcours sur un site. Plus le cheminement est limpide, plus l’utilisateur navigue aisément et les moteurs comprennent la logique des contenus. C’est ainsi que se structure un socle solide pour l’ensemble de vos thématiques.
Pour creuser cette question, s’intéresser à la notion de clusters sémantiques ouvre de véritables perspectives.
Avec Screaming Frog, l’analyse du maillage interne devient enfin concrète :
À la fin du crawl, un clic droit sur une URL et le menu « Exporter » donnent accès à deux rapports essentiels :
- Les liens entrants : ils révèlent quelles pages dirigent le visiteur (et les robots) vers une page donnée.
- Les liens sortants : on y repère tous les chemins qui partent d’une page vers d’autres destinations, internes ou extérieures.
Ces données font apparaître d’un coup d’œil les zones mal desservies ou les rapprochements à renforcer.
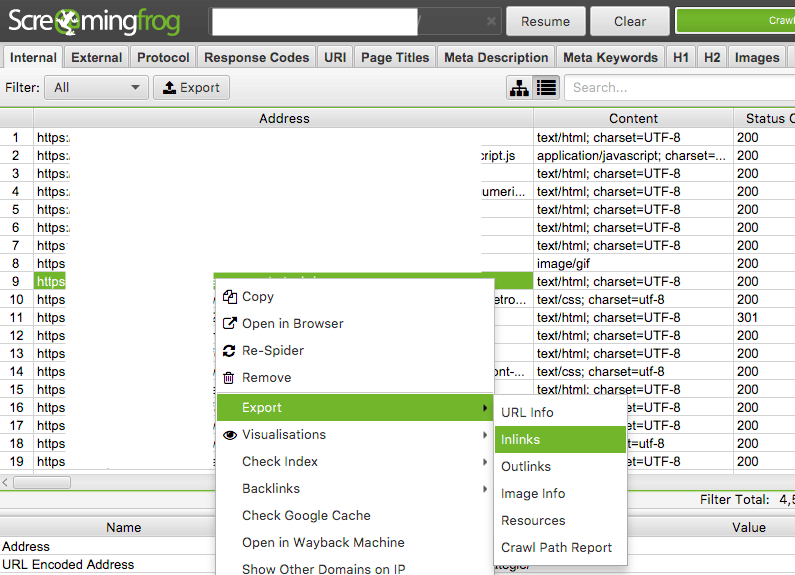
3. Repérer les redirections inutiles

Crédit : Yogi Ecommerce
Les redirections jouent un rôle lors d’une refonte ou d’un changement d’URL, mais elles s’accumulent vite et s’enchaînent parfois inutilement. À la clé : des robots ralentis, du « jus SEO » qui se disperse et une expérience visiteur alourdie.
Le meilleur scénario : relier chaque point A à son point B sans détour, plutôt que de multiplier les étapes, intermédiaires ou protocoles, qui rallongent le trajet.
En pratique, voici l’approche à suivre :
1. Exécutez le scan, puis rendez-vous dans la rubrique Rapport pour exporter le fichier des chaînes de redirection.
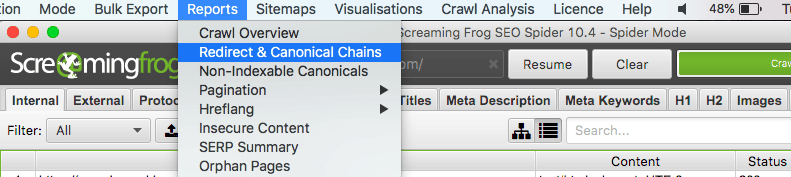
2. Ce rapport détaille pour chaque cas la chaîne complète et le nombre d’étapes : il ne reste qu’à simplifier les parcours identifiés comme trop complexes.
Ce nettoyage rend la navigation plus efficace, que l’on soit humain ou robot.
4. Observer la manière dont Googlebot traite vos pages

Tester différents frameworks Javascript et leur compatibilité avec les moteurs de recherche, Crédit : Bartosz Góralewicz
Le rendu d’une page n’est pas toujours identique selon l’interprète. Scripts, restrictions du robots.txt ou particularités de configuration brouillent parfois la perception des moteurs, et l’indexation en subit les conséquences.
Il est rassurant de contrôler, en conditions réelles, ce que Googlebot voit vraiment. C’est indispensable après une refonte technique ou sur les pages dopées au JavaScript.
L’outil facilite grandement ce contrôle :
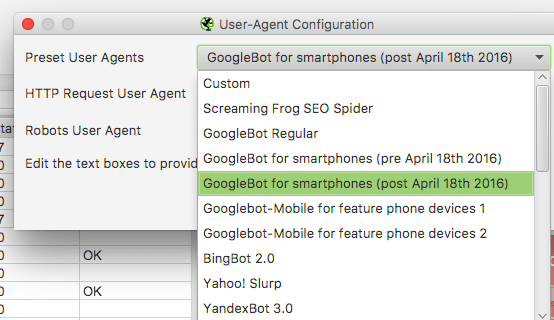
1. Sélectionnez dans les paramètres l’agent utilisateur Googlebot.
2. Ciblez l’URL à auditer et déclenchez l’analyse.
3. Dans la liste des résultats, ouvrez la page d’intérêt et faites descendre l’affichage jusqu’à la rubrique « page rendue ».
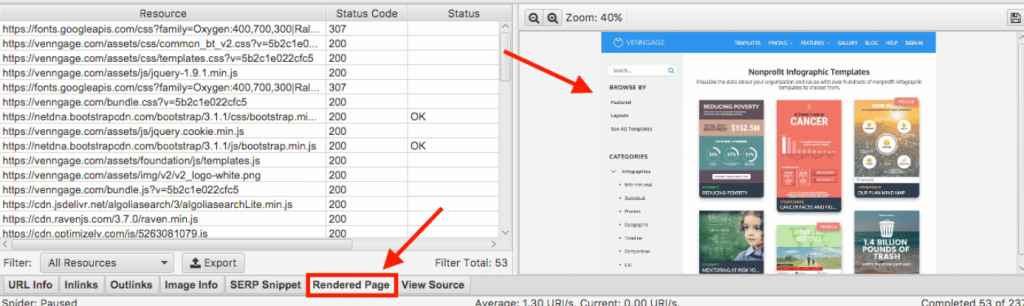
En un coup d’œil, on observe deux choses clés :
- L’apparence de la page selon Googlebot
- Les ressources chargées ou bloquées : scripts, images, feuilles CSS, et la réponse serveur associée.
Repérer ici un écart entre la version moteur et la version utilisateur permet d’agir immédiatement pour ne rien perdre en référencement.
5. Traquer les erreurs Hreflang sur les sites multilingues

Crédit : Sourcecon
Quand un site touche un public international, les balises Hreflang deviennent décisives. Mal configurées, elles perturbent Google, qui peut afficher une mauvaise version de page. Résultat : l’internaute ne voit pas le site dans sa langue, et le référencement local se grippe.
Screaming Frog repère facilement ces dysfonctionnements :
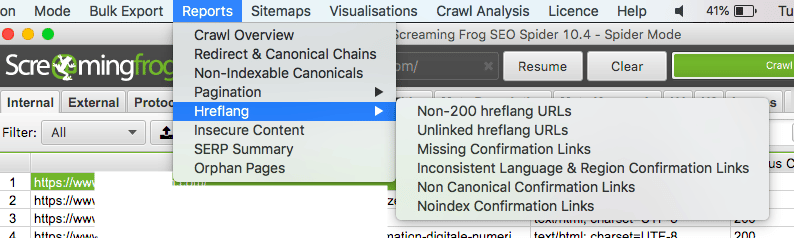
1. Allez dans le menu Rapport et ouvrez la rubrique Hreflang pour faire ressortir les erreurs spécifiques.
2. Pas d’entrée ? Les balises sont cohérentes. Sinon, certaines erreurs reviennent très souvent :
- Des balises pointant vers des pages inaccessibles ou absentes ;
- Le manque de réciprocité dans les liens Hreflang.
Ce point de réciprocité est capital : une version B doit toujours faire le lien retour vers la version A qui la référence. L’absence de « ping-pong » sème la confusion auprès des moteurs.
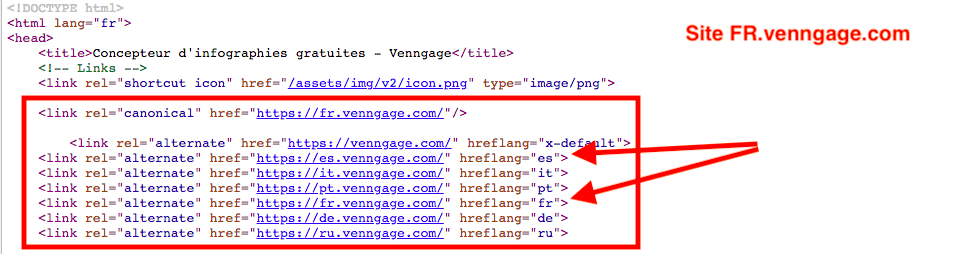 Le site fr.venngage.com en donne un exemple efficace, chaque variante linguistique renvoyant invariablement vers toutes les autres.
Le site fr.venngage.com en donne un exemple efficace, chaque variante linguistique renvoyant invariablement vers toutes les autres.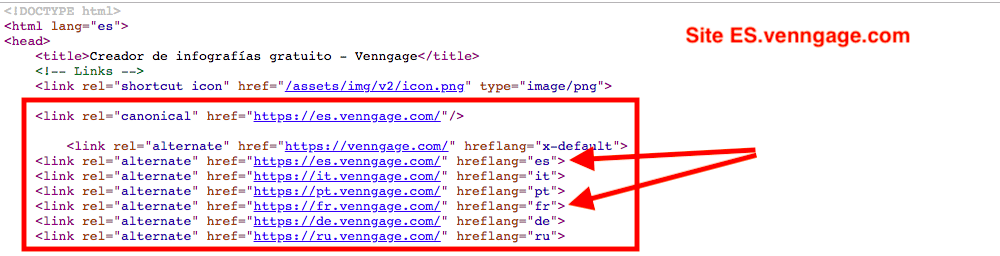
- Des incohérences sur le code région ou langue entre deux versions ;
- Des URL référencées qui ne correspondent pas à la version canonique.
6. Identifier les problèmes de contenu mixte
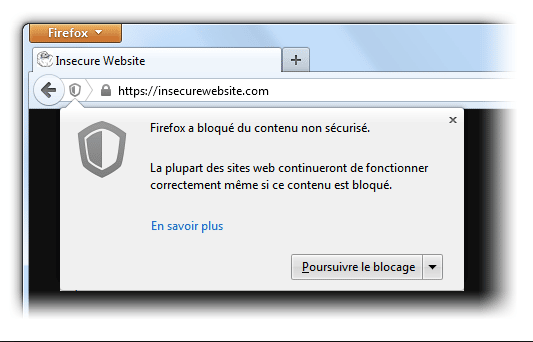
Exemple de message envoyé par Firefox lors de l’ouverture d’une page avec un contenu mixte, Crédit : Mozillazine
Héberger une page en HTTPS mais charger des ressources en HTTP, c’est donner naissance à du contenu mixte. Les navigateurs affichent des messages d’alerte, la confiance s’émousse et la sécurité devient précaire. Côté SEO, Google n’apprécie pas plus l’imprudence.
L’outil permet de les traquer sans effort :
1. Ouvrez le menu Rapport, puis exportez le fichier relatif au contenu mixte.
2. Chaque élément y figure : il suffit alors de corriger ou retirer images et scripts incriminés pour retrouver une sécurité irréprochable.

7. Évaluer la profondeur et l’accessibilité des pages
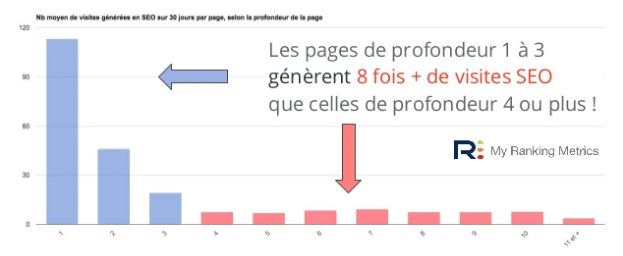
Crédit : Mes statistiques de classement
Mesurer la profondeur d’une page, c’est compter les clics qui séparent la page d’accueil du contenu final. Trop d’étapes freinent l’accès aux ressources majeures et pèsent sur la visibilité. Plus la route s’allonge, moins la page impacte le référencement global.
Pour cela, deux leviers retiennent l’attention :
- Réduire la distance qui sépare les pages clés ;
- Maintenir une organisation de navigation pragmatique et constante.
Screaming Frog offre une lecture claire de ces parcours :
1. Après le scan, effectuez un clic droit sur une URL à auditer et demandez l’export du chemin de navigation.
2. Le rapport fait ressortir pour chaque page l’itinéraire direct : à vous de voir s’il peut être raccourci sans y perdre en cohérence éditoriale.
Au moindre doute, adapter le maillage ou consolider certains accès redonne du souffle à la structure globale. Parmi les autres outils intégrés, l’analyse détaillée des sites JavaScript (pour révéler les failles invisibles côté SEO), l’optimisation des balises titre/meta ou l’audit des sitemaps XML permettent d’aller beaucoup plus loin.
Pour ceux qui veulent aller plus loin, des pistes de formation et des listes de vérification spécialisées aident à muscler sa stratégie de référencement.
- Les erreurs SEO les plus fréquentes sur les sites e-commerce
- SEO technique : 16 vérifications pour séduire Google [Checklist]
- Formation avancée en référencement
Chaque scan amène son lot de révélations, de la simple anomalie à la page oubliée qui peut soudain remonter en tête d’index. Et si la prochaine analyse bousculait votre vision du site ?